ハフマン符号化:データから最後の1ビットまで「絞り出す」技術とGzipの秘密
ハフマン符号がいかに可変長符号化と接頭符号を活用し、データを1ビット単位で最適化しているか。Gzip圧縮の核心にあるアルゴリズムの仕組みを解説します。

プログラミングの世界では、私たちはしばしばフレームワーク、アーキテクチャ、クラウドといった高度な抽象層で作業するため、最も基本的なレベルではすべてが0と1のビットに過ぎないことを忘れがちです。今週は、古 điển的でありながら非常に興味深いテーマであるデータ圧縮、具体的にはハフマン符号化アルゴリズムに立ち返ってみましょう。
1. はじめに:無駄についての物語
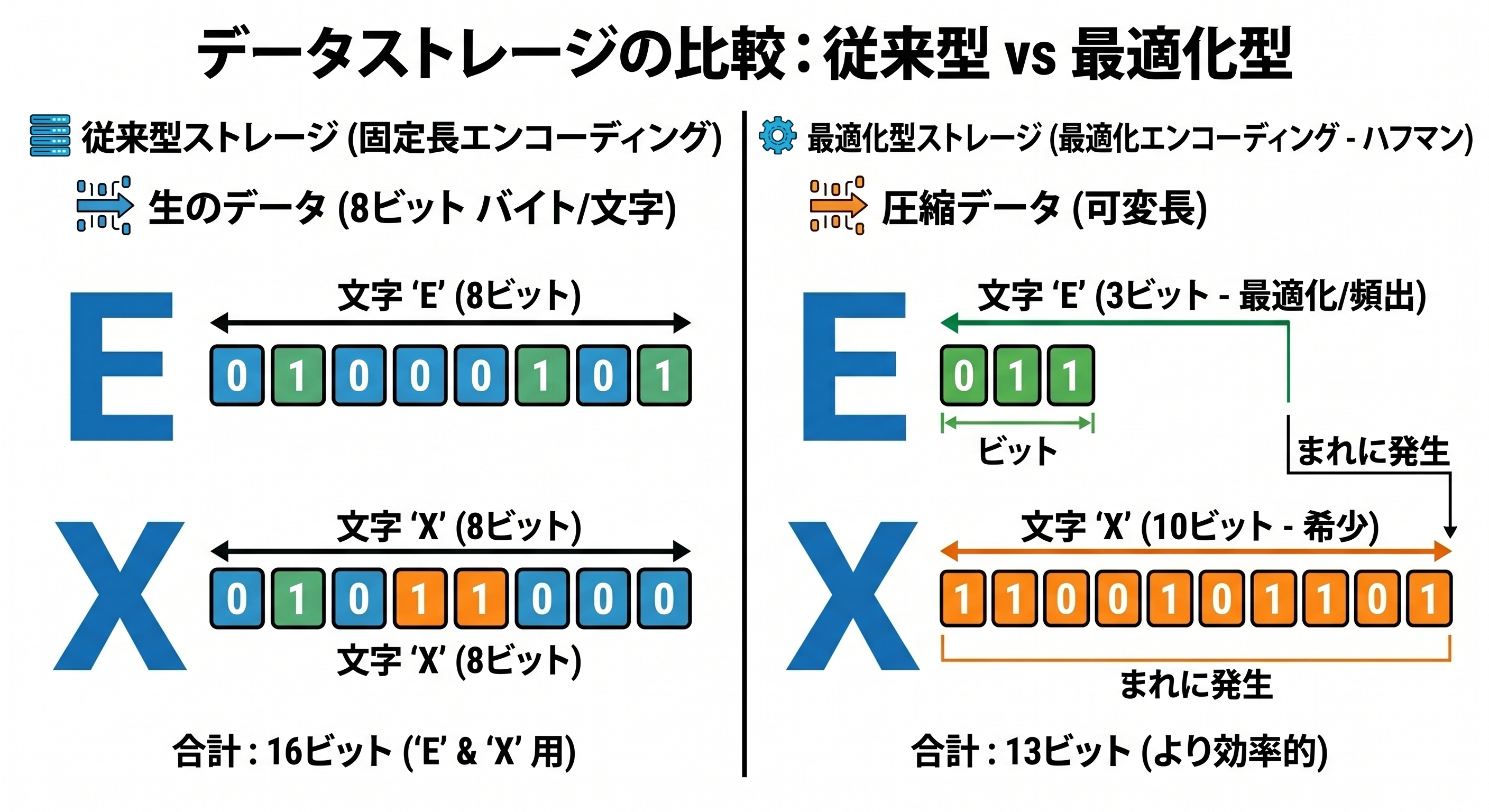
プログラマーなら誰でも、通常のASCIIやISO-8859-1標準では、各文字が正確に8ビット(1バイト)のメモリを占有することを知っています。これは公平に聞こえますが、実際には贅沢な「無駄」です。
1MBのログファイルがあると想像してみてください。その中で、キーワードERRORは何万回も出現するのに対し、Xや|のような珍しい文字は1回しか出現しないかもしれません。なぜ(非常によく使われる)Eと(非常にまれな)Xが、同じように8ビットを消費しなければならないのでしょうか?
メモリを「一等地」と考えるなら、「常連客」と「たまに来る客」に同じ面積を割り当てるのは、経済的に見て悪い判断です。Gzipのようなデータ圧縮ツールは、この無駄を許しません。そして、その最適化を助ける秘密兵器こそがハフマン符号化なのです。
2. ハフマン符号化はどのように機能するのか?
ハフマン符号化の中心的な概念は可変長符号化(Variable-length Coding)です。すべての文字を8ビットで均一に扱う代わりに、出現頻度の高い文字には「短い符号」を、まれな文字には「長い符号」を使用します。
「チャンキング」から「テープリーディング」へ
ハフマン符号化がどのようにデータを圧縮するかを理解するためには、通常のデータがどのように読み取られるかを理解する必要があります。8ビット標準では、文字aは01100001です。デコードは非常に簡単です。コンピュータは8ビットを数え、それを1つのチャンクとして切り出し、テーブルを検索するだけです。
しかし、ハフマン符号化は異なります。paranoid androidというフレーズを例にとると、文字dは3回出現し、文字pは1回しか出現しません。ハフマンアルゴリズムは、出現頻度に基づいて符号を割り当てる二分木(Binary Tree)を生成します。その結果は次のようになるかもしれません。
d=10(2ビットしか消費しない)i=0000(4ビット消費)p=0001(4ビット消費)
この時点で、符号の長さはもはや等しくありません(2ビットのものもあれば4ビットのものもあります)。では、01101010というバイナリシーケンスがある場合、コンピュータはどこで区切ればよいのでしょうか?もはや8ビットごとに「チャンク」を切り出す方法は使えません。
解決策:チャンクごとに切り刻む代わりに、コンピュータはカセットテープのようにデータを読み取り、ビットを1つずつスキャンし、ハフマン木を上から(ルートノードから)たどっていきます。ルールは非常にシンプルです。
- 木の頂点(ルート)から開始します。
- 次のビットを読み取ります。0なら左の枝へ、1なら右の枝へ進みます。
- 文字(葉ノード - Leaf node)に到達したら停止します。これで1つの文字が見つかりました。
- その文字を記録し、木の頂点に戻り、次のビットで繰り返します。
このプロセスにより、デコードは連続的な宝探しゲームに変わります。木をたどるステップを繰り返す手間はかかりますが、その代わりに膨大なストレージ容量を節約できます。
3. なぜコンピュータは決して混乱しないのか?(プレフィックスプロパティの力)
ここで、厄介な疑問が浮かび上がります。ある文字の符号が、誤って別の文字の符号の先頭部分になってしまったらどうなるでしょうか?例えば、a = 0、b = 1、c = 00という誤った符号を設計したとします。コンピュータが001というシーケンスを読み取った場合、これをaab(0 0 1)と解釈するべきか、cb(00 1)と解釈するべきか?この曖昧さはデータ全体を破壊してしまいます。
ここでハフマン符号化がその技術的な卓越性を証明するのがプレフィックスプロパティです。どの文字の符号も、他の文字の符号の接頭辞(プレフィックス)になることはありません。なぜハフマンはそれを保証できるのでしょうか?秘密は二分木の構造そのものにあります。
- 文字は「葉」(Leaf Nodes)にのみ存在する:ハフマン木では、すべての文字は枝の末端に位置します。根から葉への道のりの途中に、他の文字が含まれることは決してありません。コンピュータが文字Aを「通り過ぎて」文字Cに到達することはありません。
- 一意のパス:木の中では、根から各葉へのパスはただ一つしかありません。各文字には一意のバイナリ符号が割り当てられ、競合は発生しません。
- サイクルがない(No cycles):一方向の分岐構造のおかげで、コンピュータが無限ループに陥ることはありません。必ず葉ノードである終点に到達します。
厳密な数学のおかげで、ビットストリームが何百万文字の長さであっても、符号の長さが2ビットであろうと10ビットであろうと、コンピュータは空白や区切り文字なしで、常に100%正確にそれらを分離できます。
4. Gzipに関する「真実」:ハフマン符号化が全てなのか?
多くの人がGzipは完全にハフマン符号化であると誤解しています。実際には、GzipはDEFLATEと呼ばれるプロセスで2つのアルゴリズムを完璧に組み合わせることで、より強力になっています。
Gzip = LZ77 + ハフマン符号化
- LZ77:「探偵」の役割を果たし、繰り返されるフレーズ(例えば、何度も繰り返されるHTMLの
<div>タグ全体)を見つけることを専門とします。フレーズ全体を保存する代わりに、以前に出現した場所を指す「ポインタ」を保存します(例:50文字戻って10文字コピーする)。 - ハフマン符号化:「仕上げの塗装」の役割を果たします。LZ77が繰り返されるフレーズを整理した後、ハフマン符号化が残りの文字を圧縮し、LZ77が生成した距離(distance)も可能な限り最小のビットレベルまで圧縮します。
ハフマン符号化がなければ、Gzipはテキスト文字列のトリミングにとどまるでしょう。Gzipが最後の1ビットまで容量を「絞り出し」、私たちがウェブで日常的に使用している印象的な圧縮率を生み出しているのは、まさにハフマン符号化のおかげです。
5. 結論と教訓
データ圧縮は情報を消し去る魔法ではありません。本質的には、確率に関する数学です。
ハフマン符号化がどのように機能するかを深く理解することは、.gzや.zipファイルの背後にある驚異を解読するのに役立つだけでなく、最適化の思考を鍛えるのにも役立ちます。APIを設計したり、データベースのスキーマを計画したり、分散システムを構築したりするとき、「どのデータが最も頻繁に出現するだろうか?それをより賢く、よりコストをかけずに構造化し、表現できないだろうか?」と自問してみましょう。
この記事が、私たちのコードシステムを日々静かに駆け巡っているデータビットについて、皆さんがより興味深い視点を持つ一助となれば幸いです!