サーキットブレーカー – システムの安全遮断器
システムが急激なトラフィック増加と外部サービス障害に直面した実例を通して、Circuit Breakerパターンを解説します。障害の連鎖を防ぎ、リソースを保護し、システムの回復力を高める仕組みを学びましょう。

サーキットブレーカー:市場がパニックに陥った夜、システムを救った安全遮断器
午前2時、暗号資産市場が驚異的な大暴落(フラッシュクラッシュ)に見舞われた。BTC、ETH、SOLといったトップ通貨の価格が垂直に急降下していく。私は画面の前で大然と立ち尽くし、パニックになったユーザーが損失を抑え、ポジションを救うために私たちの取引所に殺到し、トークンをスワップ(交換)しようとする怒涛の波を眺めていた。
最も緊張が高まったその時、これら主要通貨の取引処理を連携しているサードパーティサービス「Decibel」が突然目詰まりを起こし、殺到する膨大な注文に全く応答できなくなった。UI上ではローディングの円が回り続け、ユーザーの「資産を失うかもしれない」という恐怖をさらに煽る。彼らはパニックになり、スワップボタンを何度も、何十回も連打し始めた。数百万の要求がバックエンドに押し寄せ、データベースのコネクションプールをすべて使い果たす。CPUは100%に達した。私たちの取引所が完全にクラッシュする寸前であることは明白だった。
その生死を分ける瞬間に、ソースコードから「カチッ」と明確な音が響いた。事前にシステムに仕込んでおいたサーキットブレーカー(安全遮断器)が、即座に作動したのだ。
Decibelへのリクエストが5回連続でタイムアウトしたことを静かに検知すると、この外部接続ゲートウェイが完全に麻痺していると判断し、ミリ秒の躊躇もなく回路を遮断、状態を即座に「OPEN(開路)」へと切り替えた。
次にフロントエンドから押し寄せたユーザーリクエストの津波は、コアシステムに触れることすら許されず、バックエンドの入り口で即座に遮断された。システムは即座にフェイルファスト(早期エラー)を返し、「システムが混雑しています。15秒後に再度お試しください」と通知した。
この冷徹な拒絶のおかげで、サーバーは死の抱擁から逃れることができた。目詰まりしていたコネクションプールは完全に解放され、アカウント連携や(キャッシュからの)残高表示といった他の基盤機能は生き残った。私のシステムは15秒という貴重な息吹を取り戻し、外部のDecibelサービスが安定するのを待ってから、復旧テストのために「HALF-OPEN(半開路)」へと移行する猶予を得た。システム全体の連鎖崩壊は、未然に完全に防がれたのだ。
サーキットブレーカーとは何か?
サーキットブレーカーとは、エラーが確実視される状況において、障害が発生しているサービスへのリクエスト送信を一時的に遮断するデザインパターンである。自宅にある電気のブレーカーをイメージすると分かりやすい。漏電や過電流(システムにおけるサービスのエラー)を検知すると、ブレーカーが落ちて電流(リクエスト)の通過を一時的に止める。相手のシステムが安定を取り戻すと、ブレーカーは自動的に元に戻り、再び正常な運用を再開する。
このパターンの主な目的は以下の通りである:
- エラーの連鎖を防ぐ: 1つのサービスが壊れても、他の健全なサービスまで巻き添えにしない。
- リソースの最適化: 確実に失敗するリクエストを送信してサーバーのリソースを無駄遣いしない。
- 自己修復: 定期的にターゲットのサービスに通信を試み、復旧したかどうかを自動で確認する。
- 安定性の向上: 分散システムやマイクロサービスアーキテクチャにおいて極めて重要な要素である。
3つの動作状態
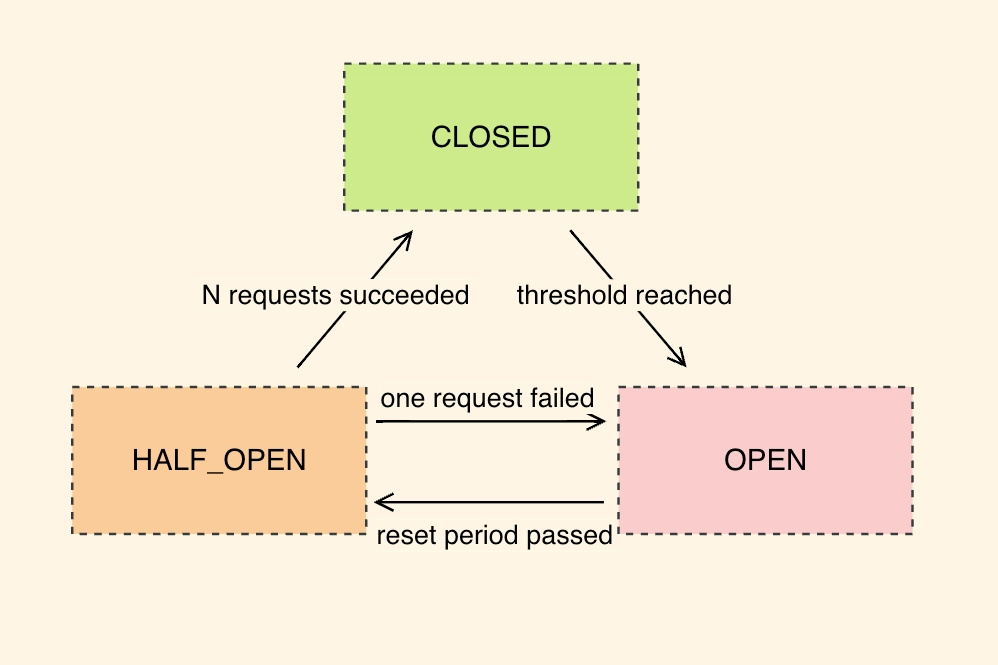
サーキットブレーカーは通常、以下の3つの基本状態で動作する:
クローズ(Closed - 閉路)
システムは正常に動作しており、すべてのリクエストは通常通り通過する。
- 内部でリクエストの失敗回数を静かにカウントする。
- 失敗数が許容ししきい値(例:3回連続失敗)を超えると、即座に「Open」状態へと移行する。
オープン(Open - 開路)
外部サービスは「停止中」とみなされ、リクエストは送信されない。
- この状態で届いたリクエストは、外部へ送られる前に即座に遮断され、エラーが返される(フェイルファスト)。
- 一定の待機時間(タイムアウト)を経て、状況を偵察するために「Half-Open」状態へと移行する。
ハーフオープン(Half-Open - 半開路)
外部サービスが復旧したかどうかを「お試し」で確認するフェーズ。
- テストとして少数のリクエストのみを通過させる。
- テストリクエストが成功した場合、システムは復旧したと判断し、元の
CLOSED状態に戻る。 - もし1度でもエラーが発生した場合、再び
OPEN状態に引き戻され、タイマーがリセットされる。
JavaScriptによる実装例
以下に、シンプルなオブジェクト指向による実装例を示す:
class CircuitBreaker {
private failures = 0;
private lastFailureTime = 0;
private state: 'CLOSED' | 'OPEN' | 'HALF_OPEN' = 'CLOSED';
constructor(
private failureThreshold: number = 5,
private recoveryTimeMs: number = 60000 // 1分
) {}
async execute<T>(operation: () => Promise<T>): Promise<T> {
if (this.state === 'OPEN') {
if (Date.now() - this.lastFailureTime > this.recoveryTimeMs) {
this.state = 'HALF_OPEN';
console.log('Circuit breaker transitioning to HALF_OPEN');
} else {
throw new HttpError(503, 'Circuit breaker is OPEN - external service unavailable');
}
}
try {
const result = await operation();
this.onSuccess();
return result;
} catch (error) {
this.onFailure();
throw error;
}
}
private onSuccess() {
this.failures = 0;
this.state = 'CLOSED';
}
private onFailure() {
this.failures++;
this.lastFailureTime = Date.now();
if (this.failures >= this.failureThreshold) {
this.state = 'OPEN';
console.error(`Circuit breaker OPEN after ${this.failures} failures`);
}
}
getState() {
return this.state;
}
}
実務での具体的な利用方法:
// 擬似的に30%の確率で失敗する不安定な外部API
const unstableApi = async () => {
const shouldFail = Math.random() < 0.3; // エラー率30%
if (shouldFail) {
throw new Error("API failed");
}
return "API success";
};
// サーキットブレーカーの初期化: 3回のエラーで開路、10秒待ってから再試行
const breaker = new CircuitBreaker(3, 10000);
const callApiWithBreaker = async () => {
try {
const result = await breaker.execute(() => unstableApi());
console.log("Result:", result);
} catch (err: any) {
console.warn("Error:", err.message, "| State:", breaker.getState());
}
};
// 挙動を確認するため、2秒ごとにリクエストを実行
setInterval(() => {
callApiWithBreaker();
}, 2000);
どのような時に使うべきか?
以下のようなシナリオで、このパターンの導入を強く推奨する:
- 外部のサードパーティAPI(決済ゲートウェイ、メール配信、SMS認証など)を呼び出すとき。
- 複数のマイクロサービスが複雑に依存し合っているシステムを構築するとき。
- ネットワーク通信が不安定、または一時的な瞬断が発生しやすい環境。
- 急激なトラフィックの急増により、下位の補助サービスがクラッシュするリスクがあるとき。
これをゼロから自作する代わりに、検証済みのオープンソースライブラリを利用することもできます:
opossum– メトリクスやフォールバック機能が充実した、Node.js用の代表的なライブラリ。cockatiel– リトライ、タイムアウト、サーキットブレーカーを備えたJS用レジリエンスライブラリ。resilience4j(Java) – Spring Bootの世界における業界標準。
実世界でのユースケース
フロントエンドにおける役割
大量のユーザーアクセスによってサーバーがボトルネックになっているにもかかわらず、クライアント(ブラウザ)が盲目的にリクエストを送り続け、すべてタイムアウトになり、結果としてサーバーが復旧不能なレベルまで完全にダウンした経験はないだろうか?まさにここでフロントエンドのサーキットブレーカーが真価を発揮する。失敗率が閾値を超えた時点でブラウザ側からのリクエストを遮断することで、サーバーに回復の余地(猶予)を与えることができる。「混雑しています。30秒後に再度お試しください」といった画面表示の裏では、この仕組みが動いていることが多い。
実際のシナリオ:
- 大規模なコンサートのチケット販売サイトを運営しているとする。
- 販売開始と同時に、数万人のユーザーが一斉にF5キーを連打する。
- サーバーが過負荷になり、504 Gateway Timeoutや503 Service Unavailableを返し始める。
- フロントエンドが座席状況を確認するための自動リクエストを裏で送り続け、サーバーの息の根を完全に止めてしまう。
サーキットブレーカーがない場合の末路:
- ユーザーによる画面更新の連打 -> 毎秒数万リクエスト -> サーバーが窒息。
- すべてのリクエストがタイムアウト -> 画面がフリーズ -> ユーザーのストレスが最大化。
- アクセスの津波が止まらないため、サーバーが自力で再起動・復旧するチャンスを完全に失う。
バックエンドにおける役割
非常に現実的な例として、従量課金制の外部サービス(OpenAIのAPIやGoogle MapsのAPIなど)をバックエンドから呼び出すケースが挙げられる。通常、相手側のサーバーエラーやタイムアウトでリクエストが失敗したとしても、リクエストが先方に到達している以上、クレジットが消費されたりクォータ(利用枠)が削られたりすることがある。サーキットブレーカーを導入しておけば、相手側の障害を検知した時点でバックエンド側が即座にリクエストを拒否(フェイルファスト)するため、失敗することが確実なリクエストに会社の予算を無駄に使い果たすリスクを防ぐことができる。
フロントエンド、バックエンドを問わず、開発チームがこのパターンを適切に導入することは、不要な通信の削減、インフラコストの保護、そしてシステム全体の堅牢性を高めるために非常に有意義である。