データ移行は一括コピーではなく設計です。三段構造で何を吸収するか
リプレイスでつまずきやすいデータ移行を、旧システム出力、吸収レイヤー、本番スキーマの三段の考え方で整理します。中間層の役割、現場でよくある2つの進め方、計画時に確認したいチェックリストをまとめています。
概要
導入
古いシステムから新しいシステムへデータを載せ替える作業は、手戻りや不整合が出やすく、多くの企業にとって避けて通れないテーマです。リプレイスや移行を検討されている方、設計や実装に関わるエンジニアの方の判断材料になればと思い、私たちが案件のなかで重ねてきた考え方を整理しました。
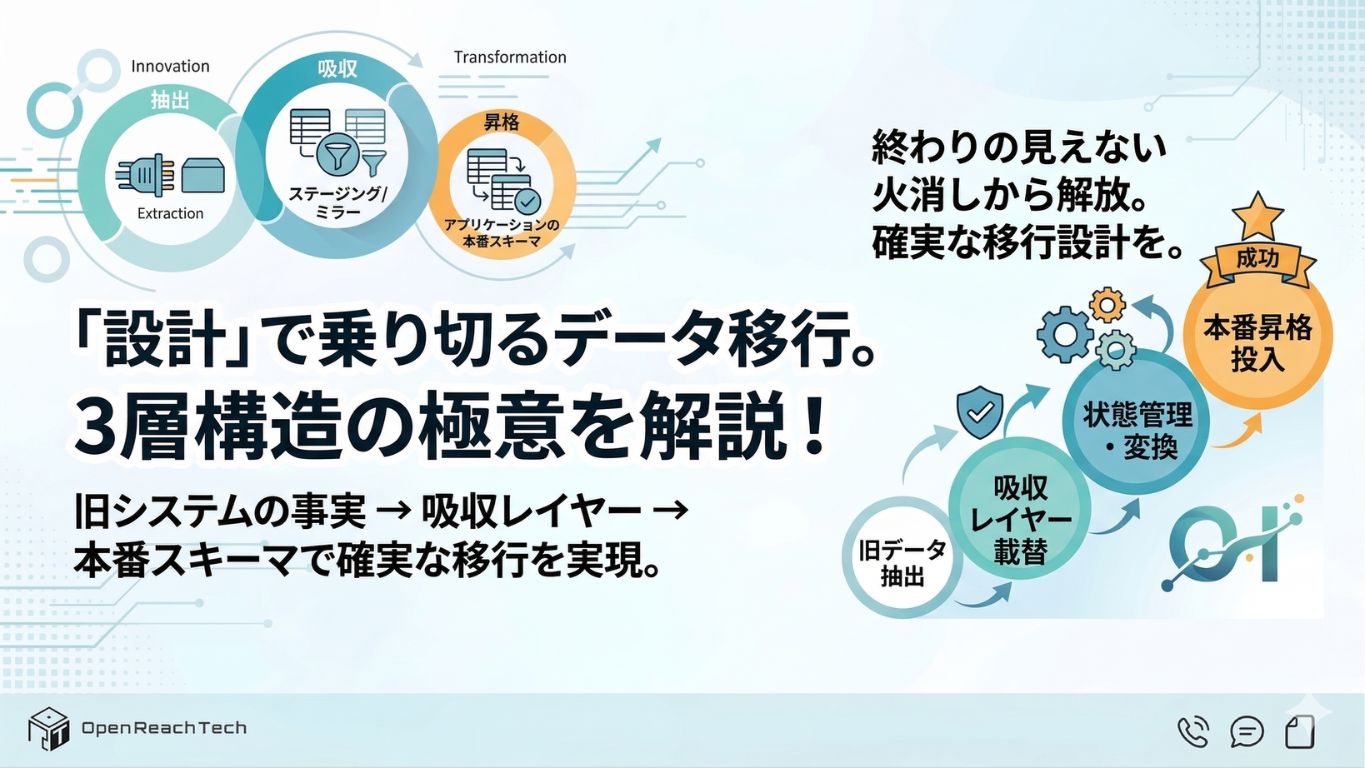
今回紹介するアーキテクチャの概要
まず結論からお伝えすると、データ移行を円滑に進めるための最大のポイントは、次の三段に分けて進めることです。
- 旧システムからデータを出す(ファイル出力やバルク抽出など)
- 吸収レイヤーであるステージングやミラーなどの中間層に、できるだけ情報を失わない形で載せる
- そこから、本番アプリケーションが前提とするスキーマへ載せ替える
旧データを新アプリに直接流し込むのではなく、吸収レイヤーを設けることで、旧データ特有のクセや移行期間だけ必要になる加工・照合を吸収レイヤーに寄せることができます。こうすると、本番側のコードやテーブルに例外処理が染み出しにくくなり、移行時の修正対応、テストの工数が飛躍的に減少します。
以下では、この3層アーキテクチャと、なぜそれが良いのかという点について少し深掘りしていきたいと思います。
なぜ本番テーブルへ直接データを入れないのか
多くの方は、古いシステムからデータをエクスポートして、新しいシステムにインポートすれば終わりだろうとイメージされるかもしれません。
しかし、実際の現場はそんなに単純ではありません。
本番データの整合性をどう担保するか、途中で失敗したときに同じ手順を繰り返せるか、データ同士の突合が曖昧なときにどう扱うか、差分だけをどう再実行するか、あとから説明できるようにどこまで残すか。こうした論点が一度に押し寄せて、単にエクスポートしてインポートすれば終わりとはいかないのが、多くの現場でのデータ移行です。移行前は動いていたのに移行後に動かなくなる不具合も珍しくなく、システムが大きいほど原因の特定と修正に時間がかかります。
わざわざ中間層なんて作らずに、直接新しいデータベースに入れればいいのではと思う方もいるかもしれません。
しかし、古いシステムには、その環境でしか成り立っていなかったデータの実情がそのまま詰まっています。古い列名や独自の識別子、担当者だけが知っている略式ルール、データの重複や欠損などです。これらは、新しく設計し直した業務データの形とは、すぐには噛み合いません。
これを無理やり本番アプリのスキーマに流し込もうとするとどうなるでしょうか。新しいシステムのあちこちに旧データ用の例外処理や複雑な分岐が染み出してしまいます。結果として、移行に失敗して再実行したり、一部のデータだけを取り直したりするたびに、保守コストが跳ね上がってしまうのです。
そこで私たちは、この複雑さを吸収レイヤーに閉じ込める形をとります。 吸収レイヤー、すなわち中間テーブルには、旧システム側にあった事実と、移行の途中で下した判断の結果をまとめて置き、本番へ渡す直前だけを新システムのルールで書くと切り出します。検証や手直し、やり直しがしやすくなるのはもちろん、あとから参加した人にもここから先が新システムの世界であることが見えやすくなります。
三段構成の流れ
具体的には、以下の3つの手順で進めます。
- 抽出 — 既存システムからファイルやバルクエクスポートなどでデータを取り出します。
- 吸収 — 取り込んだ内容を、できるだけ元の情報を失わない形で中間層である吸収レイヤーに載せます。
- 昇格 — 中間層から本番の業務テーブルへ、マッピングとビジネスルールに沿ってデータを投入します。
私たちOpen Reach Techでは、案件ごとに要件が違っていても旧システムと本番アプリのあいだに、必ず一段かませることを原則にしています。お作法というより、長く続く移行でいつ終わるか分からない手戻りに陥らないための、最初の設計で決めておきたいポイントです。
全体の流れを図にすると、次のイメージです。

吸収レイヤーが担うべき役割
この中間層に、具体的にどんな役割を持たせるか。押さえておきたいのは、おおむね次の4つです。
- 旧表現の保存 — 取り込み時点のスナップショットや旧ID、生の値をそのまま残します。これにより、監査や差分確認、手戻りが発生した際の拠り所になります。
- ID対応とひも付け — 旧IDと新IDの対応関係は、本番に投入する前にこの中間層で解決しておきます。データが紐づかない、あるいは複数紐づいてしまうといった曖昧さも、ここで状態として表現します。
- 移行専用ロジックの集約 — データの正規化やチャンク処理、つまり分割処理など、移行期間だけ必要な複雑な処理をすべてここに押し込めます。
- 運用との相性 — 何度でも再実行できるように、自然キーを使ったUPSERT、すなわち更新または挿入や、取り込みバッチIDの記録など、再実行を前提とした設計を組み込みます。
そして、本番へ載せる直前に、この条件を満たした行だけ次へ進めるという関門を決めておきます。例えば契約データなら、顧客IDと開始日が空でない、商品コードが新システムに登録済みの商品一覧に載っている、担当部署コードが組織の部門一覧に載っているといった具合です。このように、吸収レイヤーに一度全データを載せておくことで、必要なデータを絞り込む、抜けているデータの紐づけを追加するなどの処理を吸収レイヤーで対応することができ、複雑な条件分岐がアプリケーション移行のコードに漏れ出すことを防ぐことができます。
また、吸収レイヤーにOK、要確認、エラー理由などの列で各データのステータスを残しておくことで移行時のエラーの追跡も容易になり、何件が止まっているか集計したり、同じ理由の行だけ取り直したりしやすくなります。
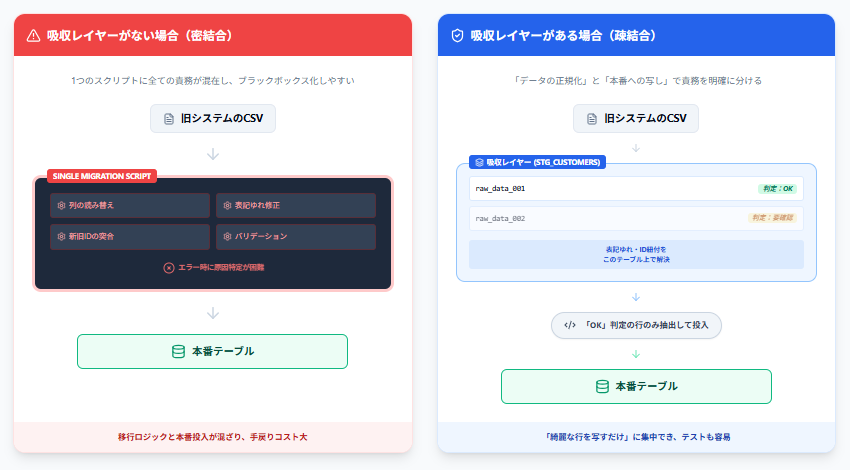
例:同じ顧客データの移行でも、責務の分け方が変わる
下記で、簡単に吸収レイヤーがある場合とない場合の差分を示します。
吸収レイヤーがない場合 — 1本の移行スクリプトのなかで、旧CSVの列の読み替え、メール表記のゆれの修正、旧顧客IDと新システムの顧客IDの突合、空欄チェックなどを続けて行い、その場で本番の customers テーブルへ INSERT します。移行専用の細かいルールと、本番アプリが普段期待しているきれいな行をつくる処理が同じ関数に混ざり、どこで原因を切り分けるかが分かりにくくなりがちです。
吸収レイヤーがある場合 — いったん stg_customers のような中間表へ、旧システムの出力どおりに載せます。別の処理で正規化、ID紐づけ、可否判定だけを更新し、本番へ回す処理は stg_customers のうち取り込み可と印を付けた行だけを customers に写すことにほぼ限定できます。旧データのクセをさばくコードと、もう整った行を本番形式で書くコードがファイルやジョブの単位でも分かれるので、移行が終わったあとに残すものも見通しよく残せます。
現場でよくある2つのパターン
ここからは、何度も現場で見てきた流れを、取り組みやすい形に2つに分けて紹介します。
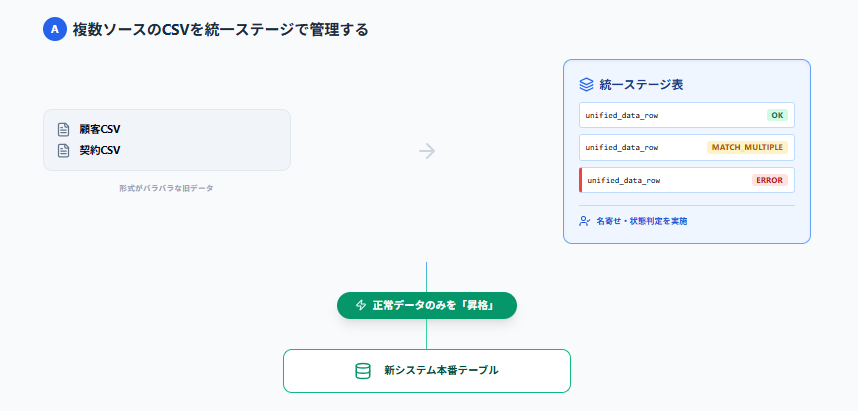
パターンA:複数ソースのCSVを統一形式のステージへ載せ、段階的に本番へ昇格する
旧システムが複数存在し、出力されるCSVの形式がバラバラといったケースによく使います。
この場合の狙いは、取り込み前の処理でバラバラなデータを統一CSV形式に揃え、ステージ上では常に同じルールで扱えるようにすることです。 例えば、顧客データと定期契約データがある場合、まずはそれぞれをステージ表に取り込みます。その後、メールアドレスの正規化などを行って本番顧客と照合し、一致しない、複数候補があるといった状態を専用の列に記録します。
最終的に、契約内容が空欄でない、商品や部門が一覧と一致するなど、あらかじめ決めた条件をすべて満たした行だけを、本番環境へ昇格させます。途中でエラーになったものは状態列を見れば一目でわかるため、長文のアプリケーションログを必死に漁る必要がありません。
パターンB:汎用SaaSのエクスポートをDBミラーに載せ、本番の業務データへ写す
古いSaaS型のCRMなどからデータを移行する際によく使う手法です。
この場合は、エクスポートしたデータを旧システムの構造に近いミラー表に一旦すべて載せます。そして、大量のデータをチャンク分割して少しずつ読み込みながら、移行プログラムであるMigratorを使って本番のテーブルへ写し替えていきます。
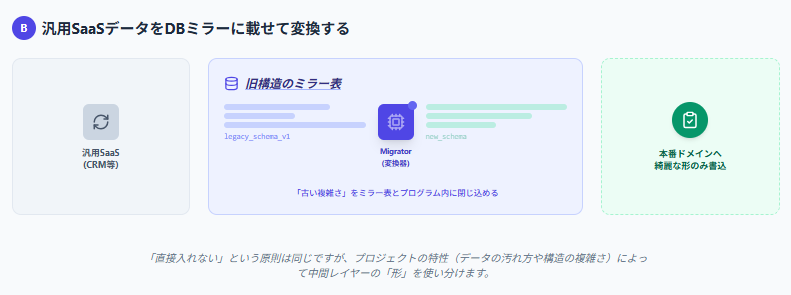
旧システム特有の複雑な形の解釈は、このミラー表とMigratorに閉じ込められるので、本番側には業務として筋の通った形だけを届けやすくなります。
2つのパターンの違い
パターンAは、状態を列に書き残しながら進めるステージ表を軸にする進め方です。パターンBは、いったん旧システムに近い形のミラーを作り、プログラム側で読み替えて本番へ載せる進め方です。 どちらが正解かというより、自社のデータの癖やチームの強みに合わせて、吸収レイヤーをどちらの形で持つかを決めるのが大切です。
データ移行を成功させるためのチェックリスト
これから移行を進める予定なら、次の点を一度リストアップしてみると安心です。
- 旧システムのデータを直接本番環境に入れない。必ず移行専用のステージかミラーを挟む。
- 同じデータを何度流し込んでも壊れないか、再実行可能かを確認する。
- 旧ID、新ID、移行途中の状態を、どのテーブルのどの列で追跡するか決めておく。
- エラーになった行の原因調査をログだけに頼らず、データベース上の状態列やエラー種別で集計できるようにする。
おわりに
うまくいくかどうかは、単にツールや一時しのぎのスクリプトだけの問題ではなく、どこを境に切るか、あとから同じことができるようにするかという設計と運用の話に大きく寄ります。
三段に分ける話は短いのですが、現場では突合が曖昧な行をどう表に残すか、やり直したときに既存データを壊さないかといった細かな決めごとが積み上がります。ここが抜けると、長引く手戻しや、発覚が遅れる不整合につながります。
Open Reach Tech株式会社では、件数が大きくなっても同じ手順を繰り返せるよう組み立てるところまで、これまでお手伝いしてきました。
リプレイスに伴う移行が初めてで不安がある、前に失敗経験があって今度は計画どおり進めたい——そんなときは、御社のデータの持ち方や体制に合わせて、吸収レイヤーと移行の段取りを一緒に整理することも可能です。
お問い合わせ
データ移行やシステム開発に関するご相談は、info@openreach.tech または当ホームページお問い合わせフォームよりお気軽にご連絡ください。