Huffman Coding: The Art of “Squeezing” Every Last Bit of Data and the Secret Behind Gzip
Explore how Huffman Coding optimizes every bit of data through Variable-length Coding and the Prefix Property—the secret behind Gzip's compression power.

In the world of programming, we often work with high-level abstractions (frameworks, architecture, cloud) and sometimes forget that, at the lowest level, everything is still just bits of 0 and 1. This week, let's return to a classic but extremely interesting topic: Data Compression, specifically the Huffman Coding algorithm.
1. Introduction: The Story of Wastefulness
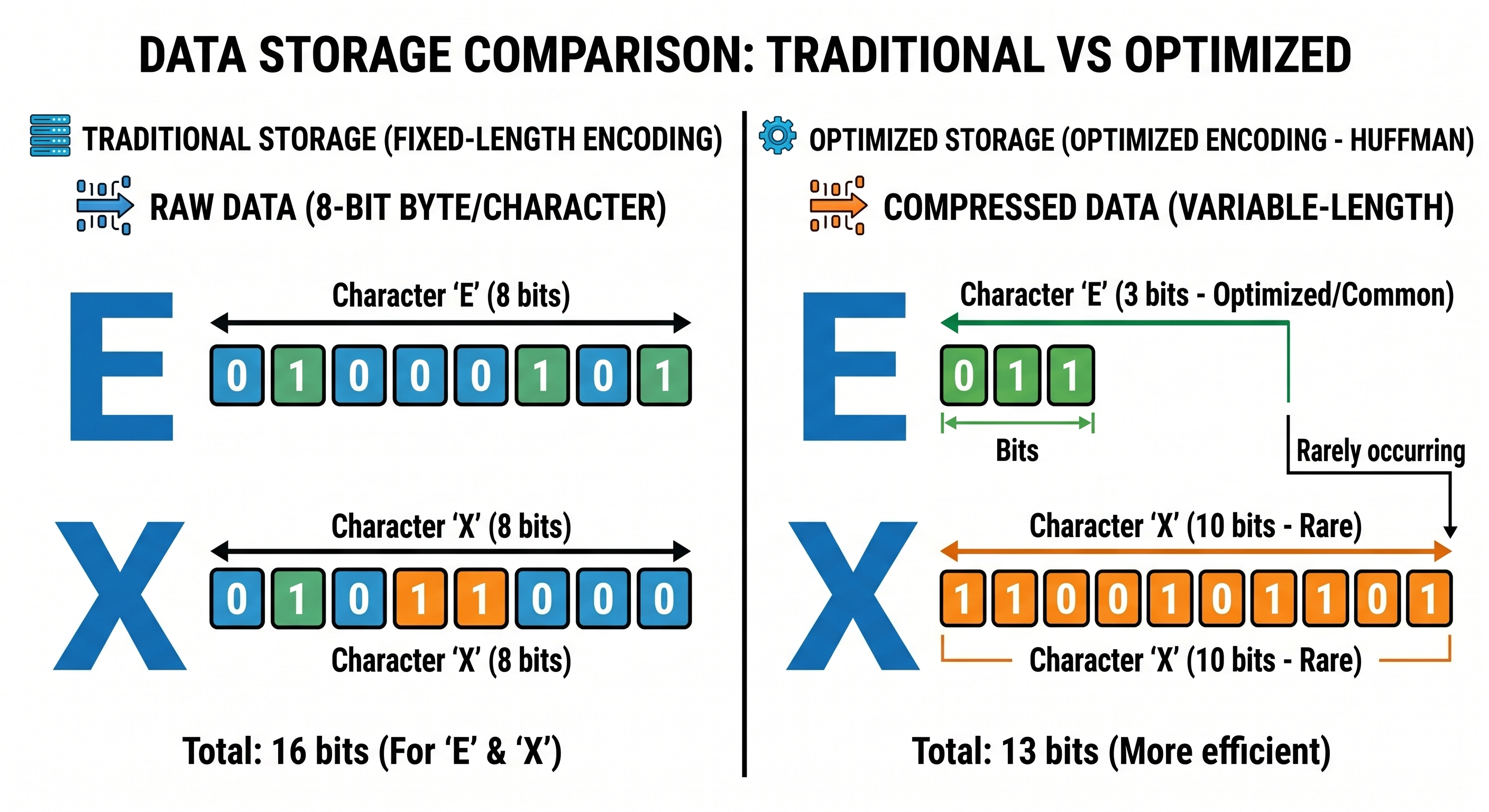
Every programmer knows that under the standard ASCII or ISO-8859-1, each character occupies exactly 8 bits (1 byte) of memory. This might sound fair, but in reality, it's a luxurious "waste."
Imagine you have a 1MB log file. In it, the keyword ERROR appears tens of thousands of times, while a rare character like X or | might appear only once. Why should the letter E (very common) and X (very rare) both take up 8 bits?
If we consider memory as "prime real estate," then allocating equal space to both "frequent residents" and "occasional visitors" is a poor economic model. Data compression tools like Gzip do not accept this waste. And the secret weapon that helps it optimize is Huffman Coding.
2. How Huffman Coding Works
The core concept of Huffman is Variable-length Coding. Instead of making every character 8 bits long, we use "short codes" for frequently occurring characters and "long codes" for rare ones.
From "Chunking" to "Tape Reading"
To understand how Huffman compresses data, we need to understand how normal data is read. With the 8-bit standard, the letter a is 01100001. Decoding is very easy: the computer just counts 8 bits, cuts it into a chunk, and looks it up in a table.
But Huffman is different. Take the phrase paranoid android as an example, the letter d appears 3 times, while p appears only once. The Huffman algorithm will create a Binary Tree to assign codes based on their frequency, and the result might be:
d=10(only 2 bits)i=0000(4 bits)p=0001(4 bits)
Now, the code segments are no longer of equal length (some are 2 bits, some are 4 bits). So if we have a binary string like 01101010, how does the computer know where to cut? We can no longer apply the "8-bit chunking" method!
Solution: Instead of chopping into chunks, the computer reads the data like a cassette tape, traversing bit by bit and moving down the Huffman tree from the top (Root node). The rules are very simple:
- Start from the root of the tree (Root).
- Read the next bit: If it's 0 -> go left. If it's 1 -> go right.
- When you reach a letter (Leaf node) -> Stop! We have found a character.
- Record that character, return to the root, and repeat with the next bit.
This process turns decoding into a sequential treasure hunt. Although it takes effort to repeat the tree traversal steps, in return, we save a huge amount of storage space!
3. Why the computer never gets confused (The power of the Prefix Property)
At this point, a tricky question arises: What if the code for one character is accidentally the beginning of another character's code? Suppose we design a faulty code like this: a = 0, b = 1, c = 00. If the computer reads the string 001, will it interpret it as aab (0 0 1) or cb (00 1)? This ambiguity would corrupt the entire data.
This is where Huffman asserts its technical prowess with the Prefix Property: No code for any character is a prefix of another character's code. How can Huffman guarantee this? The secret lies in the structure of the Binary Tree itself:
- Characters are only at the "Leaves" (Leaf Nodes): In a Huffman tree, all characters are at the very end of the branches. The path from the root to a leaf never contains another character in the middle. The computer never has to "pass through" character A to get to character C.

- Unique Path: In the tree, there is only one unique path from the root to each leaf. Each character has only one unique binary code, with no conflicts.
- No cycles: Thanks to the one-way branching structure, the computer will never get stuck in an infinite loop. It is guaranteed to reach an endpoint, which is a leaf node.
Thanks to this rigorous mathematical structure, no matter how long the bitstream is—even millions of characters—and no matter how jumbled the code lengths are (2 bits or 10 bits), the computer can always parse them with 100% accuracy without needing any spaces or delimiters.
4. The "Truth" about Gzip: Is Huffman Everything?
Many people mistakenly believe that Gzip is entirely Huffman Coding. In reality, Gzip is more powerful thanks to the perfect combination of two algorithms in a process called DEFLATE.
Gzip = LZ77 + Huffman
- LZ77: Plays the role of a "detective," specializing in finding repeated phrases (for example, a whole block of repeating
<div>HTML tags). Instead of storing the entire phrase again, it just stores a "pointer" back to its previous occurrence (e.g., Go back 50 characters and copy 10 characters). - Huffman: Acts as the "finishing coat." After LZ77 has cleaned up the repeated phrases, Huffman steps in to compress the remaining individual characters and also compresses the distances created by LZ77 down to the smallest possible number of bits.
If Huffman were missing, Gzip would only stop at trimming text strings. It is Huffman that helps Gzip "squeeze" the size down to the very last bit, creating the impressive compression ratio we use every day on the web.
5. Conclusion & Lessons Learned
Data compression is not magic that makes information disappear. In essence, it is the mathematics of probability.
Understanding how Huffman Coding works not only helps us decipher the magic behind .gz or .zip files but also helps train an optimization mindset. When designing an API, creating a Database schema, or structuring a distributed system, let's ask ourselves: "Which data appears most frequently? Can we structure and represent it more intelligently and less expensively?"
Hopefully, this article gives you a more interesting perspective on the bits of data silently running through our code systems every day!